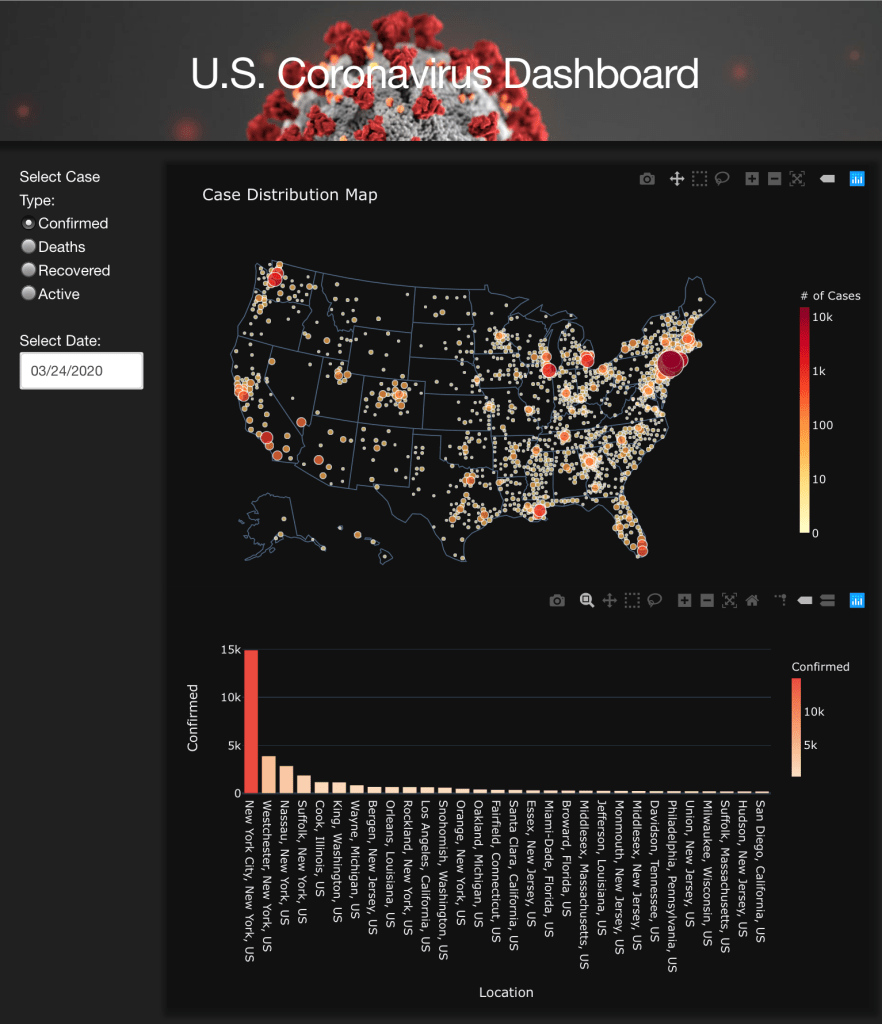
I built an interactive dashboard to help me track the status of COVID-19 in the US. It was built using Dash by Plotly and deployed to Heroku. It refreshes daily. Check it out here.
Thinking Like A Data Scientist

The Record Linkage (a.k.a. Entity Resolution) problem is a common challenge facing big organizations, where multiple sources of data are often maintained individually by separate business units. The challenge arises whenever there is a need to integrate the information from multiple data sources.
Ideally, when everything is managed in the same system (e.g., several tables in a relational database), a simple join based on the key attributes should suffice. However, in real life, different systems often maintain data in a siloed manner to suit their own needs: for instance, different formats, granularity, no exact matching fields, and unstructred data (raw text, images, etc.). All these require a smart way to link and integrate their data.
To better illustrate the problem, let’s consider the following example:
You are given two lists of online products sold on Amazon and Walmart respectively and you are asked to figure out which website sells cheaper products in general.
For simplicity, let’s assume each product record has product name, brand, description and price. A standard t-test with paired samples will suffice in the case of carefully curated data.
However, before conducting any statistical tests, we need to match the products between the two in the first place, and this turns out to be the most challenging part to solve this problem. Because for the same product, Amazon and Walmart often list different information. Even within Amazon, you can easily find listings corresponding to the same product but with different product names and descriptions. As a result, a simple string comparison between product names, brand names or descriptions won’t work properly.

To solve this problem, we will first need a fuzzy logic to compute the similarity between each possible pair of products. There are many different ways to conduct fuzzy comparison between text and below are three common options:
I will cover each of them in the next few posts with code and examples. For now, we just need to understand that these can be used to compute the similarity between two text attributes. For the example in the figure above, it may return a similarity score of 0.75 between product name “Apple iPad Pro 11-inch” and “11’’ iPad Pro (2018 Latest)”, and similarity of 0.9 between brand names, while the score between product descriptions can be fairly low at 0.15.
Once we have these attribute wise similarities, how to decide if this pair of products should be a match or not? One simplest and intuitive way is to use the sum of all the similarity scores. In the above example, the sum is 0.75+0.9+0.15 = 1.8 and we can choose a threshold, say 1.5, above which we consider the pair of products to be a match. This approach have two major drawbacks: (1) the simple sum put equal weights/importance on each attributes, which apparently does not hold in most cases; (2) the choice of the threshold is subjective.
Thankfully, a machine learning model can address these issues perfectly. The decision making process example in the lower part of the above figure addresses the first drawback via a decision tree structure, which allows assigning more weights to important attributes. The threshold at each node split can also be learned and determined through fitting a classification decision tree model (a kind of supervised learning model). This will remove subjectivity in matching and essentially address the second issue.
Note that to train such a classification model, it requires labeled data, more specifically, we need to correctly match some of the products first and use that information to teach the machine learning model to match the remaining ones. We will talk about the solution architecture in detail in another post.
Linear regression model is one of the most widely used statistical/machine learning model, because of its simplicity for model interpretation. This post will discuss about how to interpret a linear regression model after transformations. Let’s consider the simple linear regression model first:
where the coefficient 

However, in certain scenarios, transformation is necessary to make the model meaningful. For example, one important assumption under the linear regression model is the normality of the error term 
When the response y is log-transformed, (1) becomes the so called log-linear model:
Note that the log(-) above means the natural log. In this case, what does the value of 
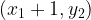
Every unit change in x would result in 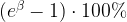


In conclusion, coefficient
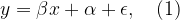
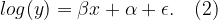
![log(y_2)-log(y_1)=\beta (x_1+1) - \beta x_1 + \alpha - \alpha \\[8pt] \Rightarrow log(\frac{y_2}{y_1}) = \beta \\[8pt] \Rightarrow \frac{y_2}{y_1} = e^{\beta} \\[8pt] \Rightarrow \frac{y_2-y_1}{y_1}=e^{\beta}-1 \approx \beta, \quad when \quad \beta \rightarrow 0. \quad (3)](https://s0.wp.com/latex.php?latex=log%28y_2%29-log%28y_1%29%3D%5Cbeta+%28x_1%2B1%29+-+%5Cbeta+x_1+%2B+%5Calpha+-+%5Calpha+%5C%5C%5B8pt%5D+%5CRightarrow+log%28%5Cfrac%7By_2%7D%7By_1%7D%29+%3D+%5Cbeta+%5C%5C%5B8pt%5D+%5CRightarrow+%5Cfrac%7By_2%7D%7By_1%7D+%3D+e%5E%7B%5Cbeta%7D+%5C%5C%5B8pt%5D+%5CRightarrow+%5Cfrac%7By_2-y_1%7D%7By_1%7D%3De%5E%7B%5Cbeta%7D-1+%5Capprox+%5Cbeta%2C++%5Cquad+when+%5Cquad+%5Cbeta+%5Crightarrow+0.++%5Cquad+%283%29&bg=ffffff&fg=000000&s=1&c=20201002)
